Cover image created through Copilot
Feature engineering is a make-or-break step in the machine learning pipeline, but even seasoned practitioners can fall victim to a subtle yet devastating mistake. While labeling or transforming data may seem like a straightforward task, a common pitfall lurks in the shadows, waiting to undermine your model’s performance in ways you might not expect. This often overlooked issue can lead to a phenomenon known as “look-ahead bias,” where your model inadvertently gains access to information it shouldn’t have during training. In this post, we’re going to talk about what this pitfall exactly is and how to address it.
Previous researches
- 【Momentum Trading】Use machine learning to boost your day trading skill - meta-labeling
- 【Momentum Trading】Yes or No? Adopting the Supertrend indicator in your trading strategies?
- Looking for no-loss trading strategy? Here’s the strategy that you should look at
What this pitfall is about?
Winsorizing, min-max scaling, standardization scaling, outlier handling, and other transformations are all techniques of feature engineering that are used to improve the quality of the data and then further improve the performance of the machine-learning model. The modern coding tools and packages make these techniques easy to implement. However, there is one place that is easily overlooked while conducting the feature engineering above and then creates the so-called look-ahead bias.
Let’s consider an example to better understand the concept of look-ahead bias. Suppose we want to create a binary target variable (Y) for our machine learning model based on the historical stock prices. We plan to label each data point as True if the corresponding daily price falls within the top 30th percentile of the entire dataset, and False otherwise. This labeling process is a form of target encoding or target transformation, which is a common step in supervised learning tasks.
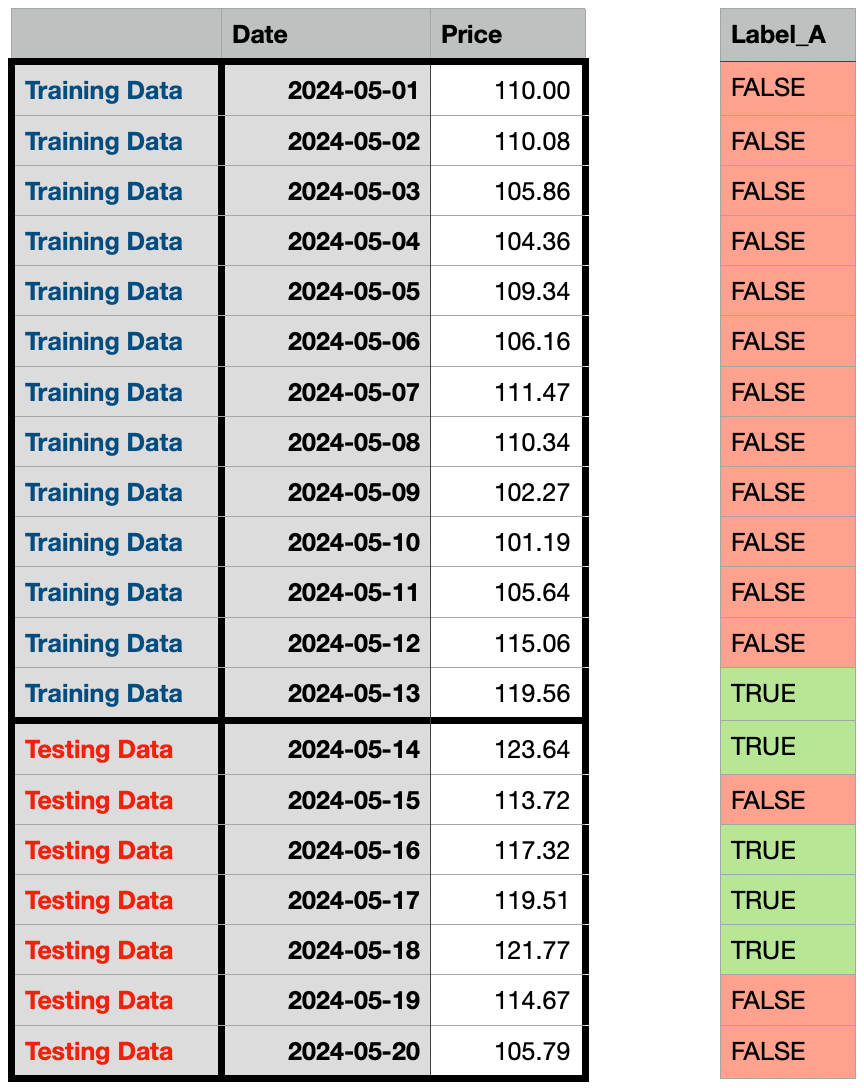
Labeling each data point according to its percentile
At first glance, this seems like a straightforward approach. However, there is a subtle but crucial place that we need to be careful of. In the above approach, we are trying to find the data points whose price is in the top 30% percentile among the entire dataset, meaning the data points in the testing dataset are also being considered in the labeling process. This could lead to:
- As you can see in the above table, there is only one data point marked as
Truebecause most of the data points in the top 30% percentile are in the testing dataset. This would create a very imbalanced dataset for our machine-learning model to be properly trained. - The purpose of the testing dataset is to evaluate the performance of the model on unseen data. However, in this case, the testing dataset is also used to label the data points. This can lead to a situation where the model is being trained on data that it has already seen, which can result in overfitting and poor generalization.
How do we address it?
To address this issue, we can modify the labeling process to only consider the data points within the training dataset. This would ensure that the testing dataset is not used to label the data points, resulting in a more fair and accurate evaluation of the model’s performance. Let’s have a look at the results below.
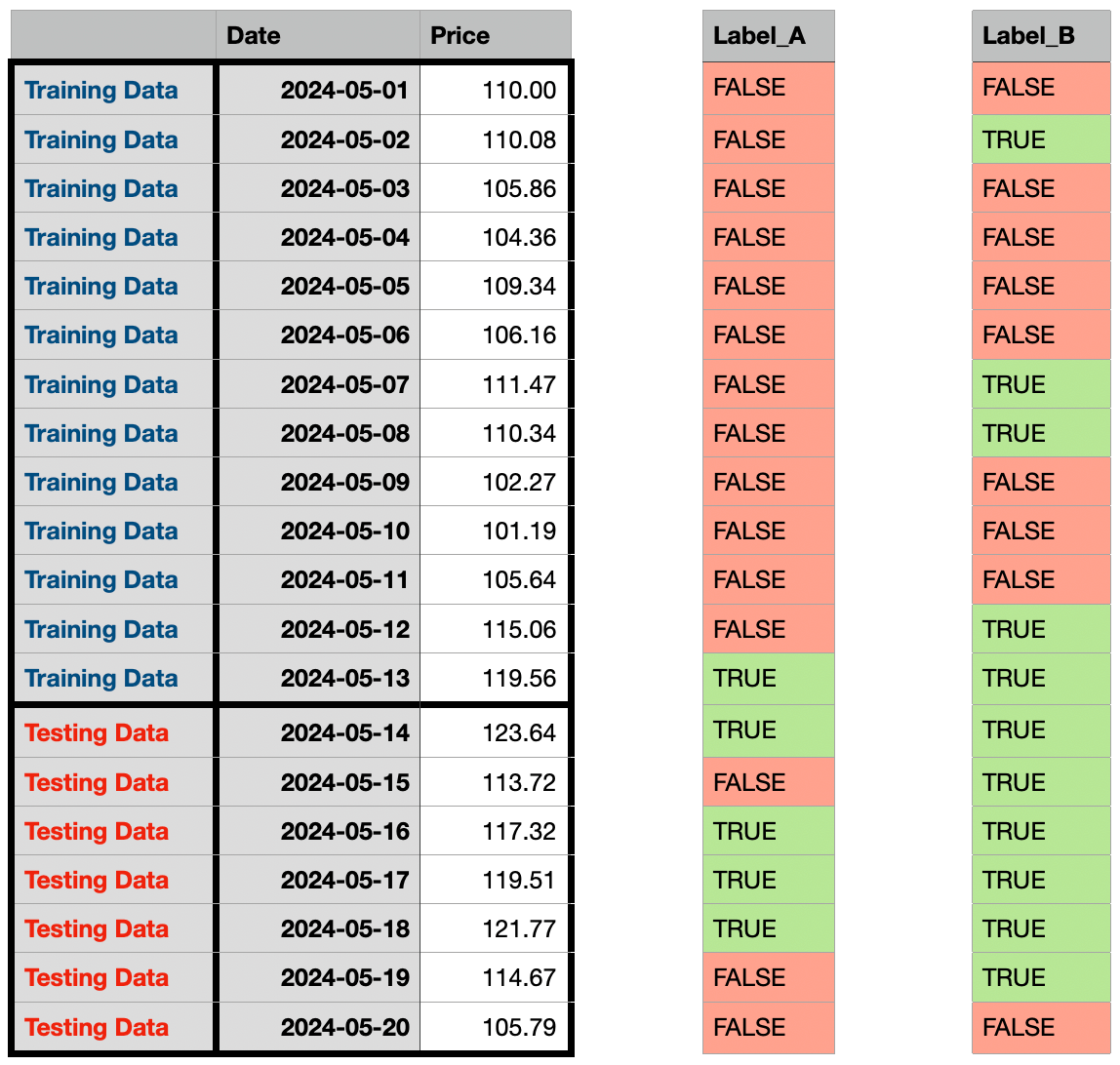
Labeling each data point according to its percentile within the training data period
See? In our second approach, we only consider the data points within the training dataset, and the testing dataset is not used to label the data points. Then we used the pattern learned from the training dataset and labeled the data points in the testing dataset, in which we created a much more balanced training dataset. The results produced are drastically different when looking at the labels of the testing dataset.
How do we implement it?
So how are we going to incorporate this into the feature engineering part of our machine learning pipeline? If you have experience with Sklearn, the answer is quite obvious and easy: we separate the entire labeling or transforming step into fit and transform. Pretty much in every transform function of Sklearn has three methods: fit, transform, and fit_transform.
- The
fitmethod is to pick up the pattern you design from the training dataset. - The
transformmethod is to apply the learned pattern to transform/label the given dataset. - The
fit_transformmethod is used to learn the pattern from the given dataset and then transform the other given dataset using the just-learned pattern.
Let’s have a look at my implementation of a customized labeler class below. This labeler is to label the top N% percentile to your designated value and label the rest to any other value.
First, you import the necessary libraries.
1
2import pandas as pd
import numpy as npDefine a
DataLabelerclass to contain the methods we mentioned above.1
2
3
4
5
6
7
8
9
10
11
12class DataLabeler:
def __init__(self):
pass
def fit(self):
pass
def transform(self):
pass
def fit_transform(self):
passIn the
__init__(self)method, we define the column names of both the independent variable and dependent variable. Also, we will need variables to memorize the pattern we learned from the given dataset.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class DataLabeler:
def __init__(
self,
target_col:str='rtn',
result_col:str='rtn_bin',
conditions:list=[0.7],
categories:list=[0, 1]
):
self.target_col = target_col
self.result_col = result_col
self.conditions = conditions
self.categories = categories
self.boundary = None
if len(self.categories) != len(self.conditions) + 1:
# Raise error if your conditions and categories are in the wrong shape
raise ValueError(f'The number of categories should have one more than the number of the boundary')Implement the
fitmethod, using the given data to calculate and memorize the boundary value.1
2
3
4class DataLabeler:
def fit(self, data):
series = data.loc[:, self.target_col]
self.upper_bound = series.quantile(self.conditions[0])Implement the
transformmethod, transforming the given data into the proper label based on the trained pattern. Here I won’t do it again for thefit_transformmethod, as it is simply a combination of bothfitandtransformmethods.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class DataLabeler:
def transform(self, data, inplace=False):
if not self.upper_bound:
raise ValueError(f'The labeler was not trained yet')
# This inplace flag to decide whether to perform the work on the original dataframe or a copy of it
tmp = data.copy() if not inplace else data
series = tmp.loc[:, self.target_col]
cond = [
(series < self.upper_bound),
(series >= self.upper_bound)
]
tmp.loc[:, self.result_col] = np.select(cond, self.categories)
return tmp
Finally, let’s have a look at how we instantiate the labeler class and use it to label the data.
1 | # Initialize the parameter needed |
Conclusion
This concept can not just be applied to labeling, but also to other transforming techniques, such as IQR winsorizing and standardization scaler, that you wish to customize as you need. I will leave the implementation of the fit_transform method as an exercise for you to try. Remember, there is no right answer or process in the realm of machine learning. You need to figure out the best way to solve the problem you are facing instead of using the one-size-fits-all approach.


