
Photo by Shutterstock
In this article, we will discuss how sentiment analysis impacts the financial market, the basics of NLP(Natural Language Processing), and showcase how to process the financial headlines by batch to generate an indicator of the market sentiment.
Become a Medium member to continue learning without limits. I’ll receive a small portion of your membership fee if you use the following link, at no extra cost to you.
If you enjoy reading this and my other articles, feel free to join Medium membership program to read more about Quantitative Trading Strategy.
What is Sentiment Analysis
Imagine this,
You are a top-notch trader on the Wall Street. One day morning, you were reading the newspaper while sipping a cup of Americano from your favorite mug. You’re enjoying the beautiful sunlight shed on you. Suddenly, one piece of news grabbed your attention. The news seemed to be talking about the newly released product and financial forecast of the company. After reading the whole piece, the pessimistic tone throughout the article started worrying you. You stroke your chin and started contemplating, “Maybe I should dump the shares that I purchased yesterday”…

Contemplation photo by Darius Bashar on Unsplash
This is the perfect example of sentiment analysis. When you receive a piece of information, you start reading it and conducting analysis not just based on the intel hidden inside the information, but you also make the judgment using the sentiment you get from the words and punctuation in the sentence. Sentiment analysis is essentially the process of analyzing digital text to determine whether the emotional implication of the message is positive, negative, or neutral. The sentiment you extract from the text can help you further improve the accuracy of your decision-making process.
What is the application of Sentiment Analysis in the financial market
The emotions of the investors mostly drive the financial market and they are usually influenced by the news released by the companies or the reporters. As the technology evolved, we’re in an information explosion era that the text-format intel will need to be processed by machine rather than by manpower. Therefore, there are already a lot of companies and organizations using machines to process the company press release, annual financial report, or even forum comments to build up a clear idea of where the public opinions are heading. In order to enable machines to do that, there are a lot of linguistic techniques that need to be applied. Thankfully, we already have a lot of mature technology and theories out there for us to choose from. All these tools, techniques, and theories are now under the hood of “NLP” (Natural Language Processing).
NLP Introduction
NLP is an interdisciplinary realm of computer science and linguistics, and the scholars in this field are dedicated to summarizing the languages we use into linguistic rules and then teaching computers to understand and even speak the languages. Currently, there are already AI products built to be able to conduct conversations with humans, such as ChatGPT from OpenAI, Bard from Google, and Claude from Anthropic. These are all state-of-the-art AI products for users to apply to their daily lives. However, we won’t be touching any of these in this article. Instead, we’re going back to the basics using NLTK (Natural Language Tool Kit) to showcase how we can transform a sentence into a number-based sentiment score to help us be better informed than the other retail investors..
As said, the goal is to process our language into the binaries that computers can understand. This is the so-called vectorizing ofgiven text. Once the text has been vectorized into a series of numbers, the serialized numbers can be treated as features and fed to the machine-learning model. Then, the following are the things that we get used to, such as feature engineering, model training, and result predicting. Before vectorizing the text, there are several steps to go through as the image demonstrated below: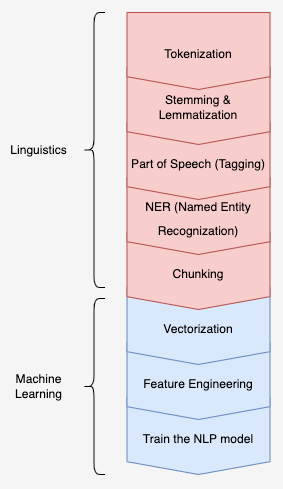
NLP processes to vectorize text
Tokenization
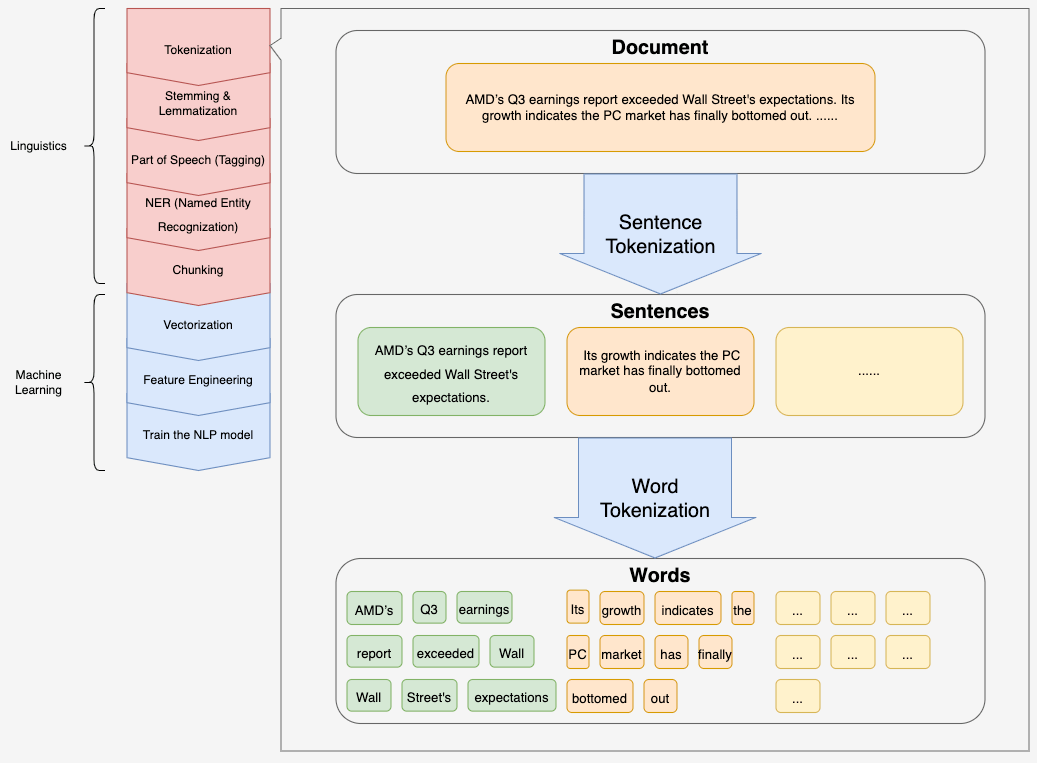
NLP processes: Tokenization
Tokenization, as the name suggests, is to break the sentence into words and to standardize these words into tokens that can be treated unanimously with the following steps:
Split the document/sentence word by word
This would be the very first step to process the text-based document input.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import nltk
# This is the lexicon for processing text. We're going to talk about it later
nltk.download('punkt')
corporas = "AMD’s Q3 earnings report exceeded Wall Street's expectations. \
Its growth indicates the PC market has finally bottomed out. ......"
print(nltk.sent_tokenize(corporas))
["AMD’s Q3 earnings report exceeded Wall Street's expectations.",
'Its growth indicates the PC market has finally bottomed out.',
'......']
print(nltk.word_tokenize(corporas))
['AMD', '’', 's', 'Q3', 'earnings', 'report', 'exceeded', 'Wall', 'Street', "'s", 'expectations', '.', 'Its', 'growth', 'indicates', 'the', 'PC', 'market', 'has', 'finally', 'bottomed', 'out', '.', '......']
Now you can see that all the words and punctuations are split into individual words. However, these words are not yet ready as there are irregular symbols or characters in the list that actually have no meaning at all. Therefore, we need to remove them from our token list.
Remove symbols and punctuation
In the token list above, we see a lot of punctuations such as ', ., or ... scattered here and there throughout the list. Even though they do mean something when they are combined into a sentence, removing them actually won’t prevent us or the machine from understanding the general structure of the sentence.
1 | tokens = [x for x in nltk.word_tokenize(corporas) if x.isalpha()] |
Remove stop words
Stop words are a set of common words that add much meaning to a sentence. For example, if you want to know “how to cook a piece of steak with a oven”, you probably google with keywords cook, steak, and oven. How, to, a, of, and with would be considered stop words as they contain less information than the rest of the words. The stop words are actually used in every language (but maybe not in programming languages lol).
1 | from nltk.corpus import stopwords |
See! The tokens now look more unified, and would not prevent us from understanding the exact meaning of this sentence. Here we finish the first step of the processing.
Stemming & Lemmatization
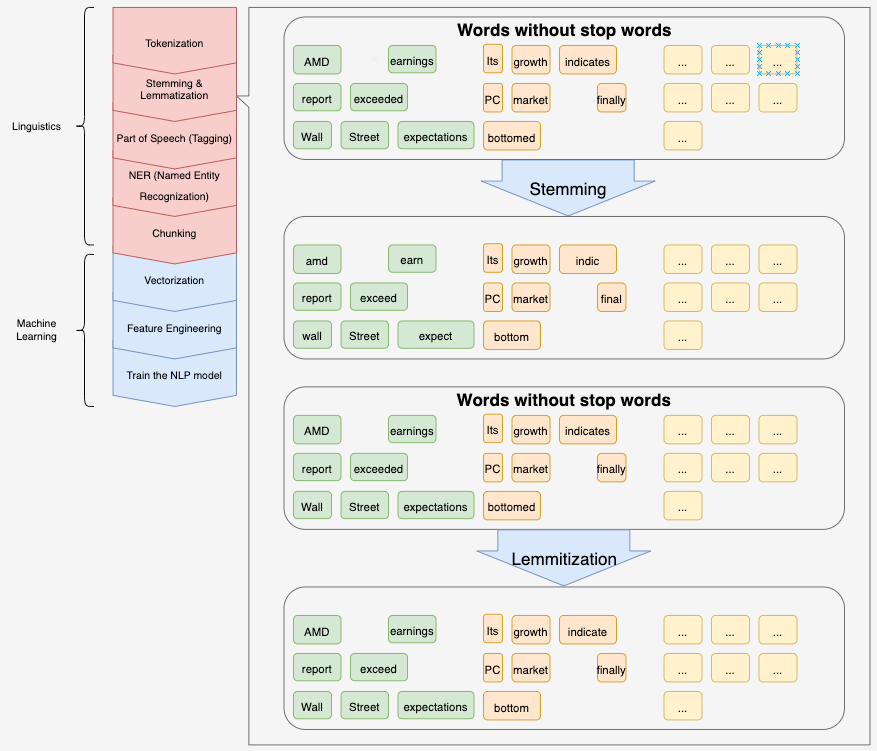
NLP processes: Stemming and Lemmatization
The English language has many variations of a single common root form. For example, the word love has forms of loves (verb.), loved(verb.), loving(adj.), loves(n). These variations do help human beings comprehend the context of the speakers’ intentions but inevitably create ambiguity for the machine-learning model to grasp the key point in the document. Therefore, it’s crucial to further process these variations and then convert them to an identical form that won’t confuse the machine learning model. Stemming or lemmatization are the techniques that facilitate finding the common root form of word variations in different ways, but ultimately they both aim to achieve the same goal.
Lexicons
First of all, let’s talk about lexicons. Lexicons are the fundamentals of the stemming and lemmatization techniques. It is like a dictionary to look up when finding the root form of a word variation. Therefore, choosing the right lexicons to use is very crucial for processing the words in the given document. LIWC, Harvard’s General Inquirer, SeticNet, and SentiWordNet are the most famous lexicons. Loughran-McDonald Master Dictionary is one of the most popular economy lexicons. SentiBigNomics is a detailed financial dictionary specialized in sentiment analysis. There are around 7300 terms and root forms documented in this lexicon. Also, if you’re looking to conduct sentiment analysis against the bio-medical paper, WordNet for Medical Events (WME) could be your better choice.
Stemming
Stemming is a process to reduce the morphological affixes from word variations, leaving only the word stem. The grammatical role, tense, and derivational morphology will be stripped away, leaving only the stem of the word, which is the common root. For example, both loves and loving will be stemmed back to the root form love. However, stemming has its dark side that sometimes will backfire. The words universal, university, and universe have different meanings, but share the same root form univers if you adopt the stemming method. This is the price you have to pay because stemming offers a faster and easier way to extract text features.
1 | from nltk.stem import PorterStemmer |
Lemmatization
On the contrary, lemmatization can better discover the root form of the word variations with the cost of sacrificing the performance of speed. Lemmatization uses a thicker lexicon to compare and match with to find out the root form. Hence, it’ll return a more accurate word compared to stemming. Also, lemmatization also takes the part of speech into consideration. For example, lemmatize saw will get you see if you treat it as a verb and saw if you treat it as a noun.
1 | from nltk.stem import WordNetLemmatizer |
One thing that is worth talking about is, that unless you have faithful confidence knowing your model needs both these techniques come into play, you probably don’t want to use these two techniques at the same time. For example, the stemming method will strip the word saws down to saw, which makes sense because saws is a plural format of the noun saw. If you then try to apply lemmatization to the word saw, you might get see if you didn’t specify it as a noun. So be aware.
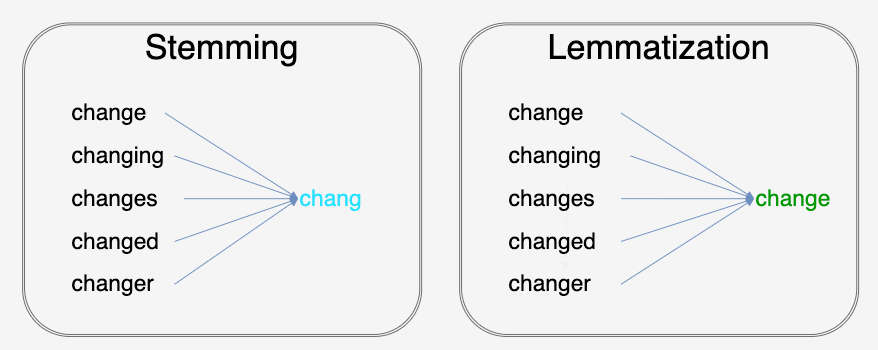
Differences between stemming and lemmatization
Part-of-speech tagging
After learning the power of lemmatization, you probably wanna ask, “Hey! If I’m going to specify the part of speech of every single word, that is no longer efficient at all”. Worry not. NLTK is well-thought-out and has built this part-of-speech tagging as one of its sub-packages. You simply pass your tokens as parameters into nltk.pos_tag() function and the pre-defined part-of-speech tag will be returned together with the tokens as tuples. You can then further define a function to replace the returned pos tag with the simple set of [n, v, adj, adv, conj, ...], making lemmatization much more easier.
1 | nltk.download('averaged_perceptron_tagger') |
NER (Named Entity Recognition) and chunking
What is NER (Named Entity Recognition)? Easy. Take the New York Statue of Liberty for example. Should we tokenize this into New, York, Statue, of, and Liberty, or should be New York and Statue of Liberty instead? The named entity is the unique name for places, people, things, locations, etc. This combination of words shouldn’t be treated as multiple tokens. Instead, it should be treated as one token. That’s why we need to regroup the words and find out the named entities, reducing the chances of confusing our following steps.
1 | nltk.download('maxent_ne_chunker') |
See! Wall Street has been put together into one word as a named entity.
OK!
I’m going to stop it right here. After all, we don’t need all the steps in place to conduct a simple sentiment analysis. We’ll now jump right into the simple sentiment analysis tool to evaluate the emotional implication of the news headline. However, if you want to know more details about the details of the rest of these steps and also how to apply them in the stock market, feel free to leave a message to me.
VADER (Valence Aware Dictionary and sEntiment Reasoner)
VADER is a model built in NLTK package that aims to evaluate the emotional intensity of a sentence. VADER not only determines whether a sentence is positive or negative, but it also evaluates the intensity level of the sentence, judging how positive or negative is a given sentence. Here are a few more things about VADER:
VADERreturns four values for each sentence evaluation: positive level, negative level, neutral level, and compound score.- It takes into account of the emotional impact of special punctuations like
!!!and!?and also the emojis such as:)and;(. - It also factors in the impact of the all-capitalized characters which enhance or dampen the emotional implication of a sentence.
- It’s fast as it doesn’t need to train any model before using it
- It’s best suited for the language used in social media because of its excellence in analyzing emojis and unconventional punctuation.
1 | %-) -1.5 1.43178 [-2, 0, -2, -2, -1, 2, -2, -3, -2, -3] |
vader_lexicon.txt is used for finding the corresponding score of a word or a punctuation
The scoring method that VADER used and its source code are relatively straightforward and easy to understand. I would encourage you to spend half an hour to get to know what VADER does when it comes to evaluating the sentiment score. (Check out the VADER source code).
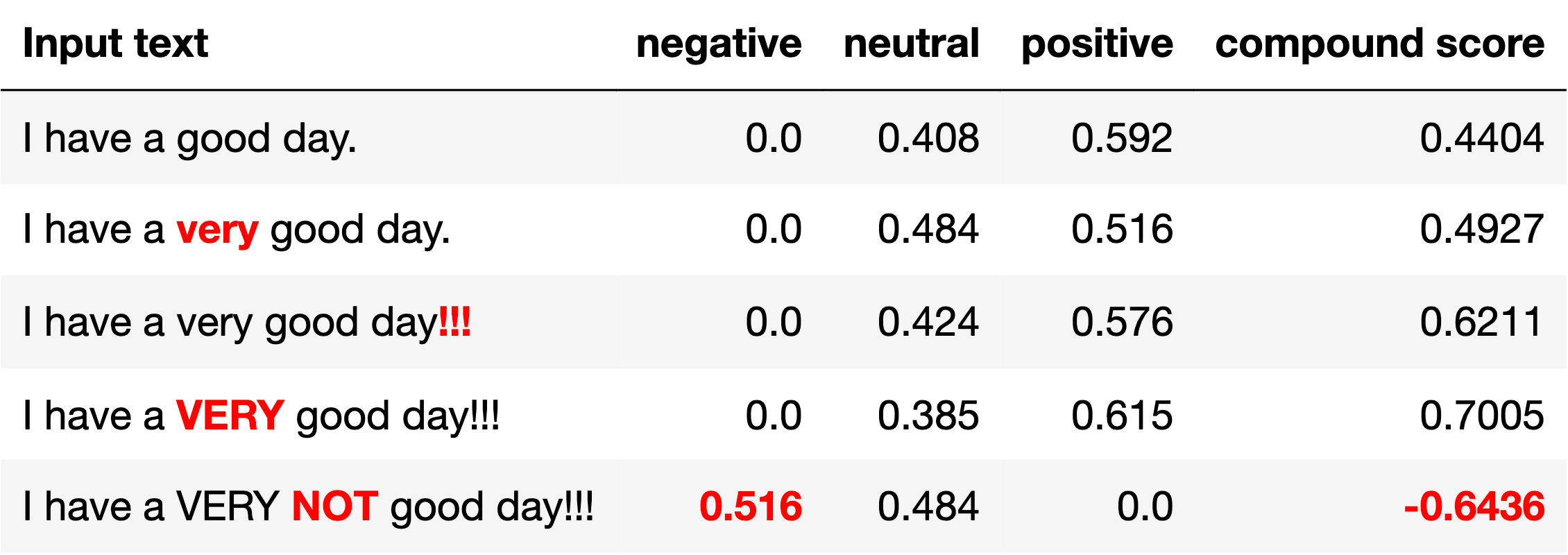
A couple of examples of VADER polarity_scores()
Get started with the stock sentiment analysis
Let’s get down to business! I’m going to demonstrate how to conduct sentiment analysis with VADER against four stocks: NVDA, AVGO, AMD, BABA. As for the data sources of the news headline, I will scrape from the https://finviz.com/ as suggested by the author of this article.
Step 1. Global variables
First, let’s import the libraries we need, and define the tickers that we’re going to look into.
1 | import pandas as pd |
Step 2. Fetch the headlines of the tickers
In this step, we use BeautifulSoup and requests to scrape the news headline from https://finviz.com/. After you scrape the headlines and tuck them into the pd.DataFrame, you will notice that most cells in the Date column are actually empty. That is because the date format in the https://finviz.com/ causes this issue. Hence, we need to further process the data in Date column and extract the time data to fill in the Time column. Once that is done properly, we can now concatenate all the scraped headlines to produce a complete headline table.
1 | news = pd.DataFrame() |

DataFrame of the scraped headlines
Step 3. Generate the news sentiment score
This step will be fairly simple. We apply the polarity_scores() function to all the headlines. Once we get all the negative, neutral, positive, and compound scores, we concatenate them back to the original news dataframe. Notice, here we need to download the vader_lexicon first so that the polarity_scores() function can work properly. The way that vader package calculates the score is quite interesting and not difficult to understand. If you are interested in knowing how the scores get calculated, read the VADER source code. Probably will take you half an hour to do so, but it will definitely pay off.
1 | nltk.download('vader_lexicon') |
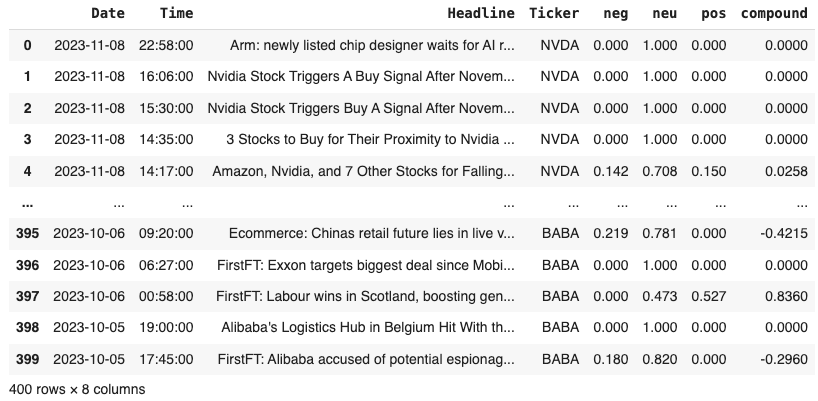
Attach the score back to the original DataFrame
Step 4. To further add a flavor to the sentiment score
It is kind of a well-known fact that the impact influence of any newly released news will wane away as time passes. I use the EMA (Exponential Moving Average) method to factor this phenomenon into our sentiment score model. Here I adopt the 5-day EMA to calculate the sentiment score moving average.
1 | news_score = scored_news.loc[:, ['Ticker', 'Date', 'compound']].pivot_table(values='compound', index='Date', columns='Ticker', aggfunc='mean').ewm(5).mean() |
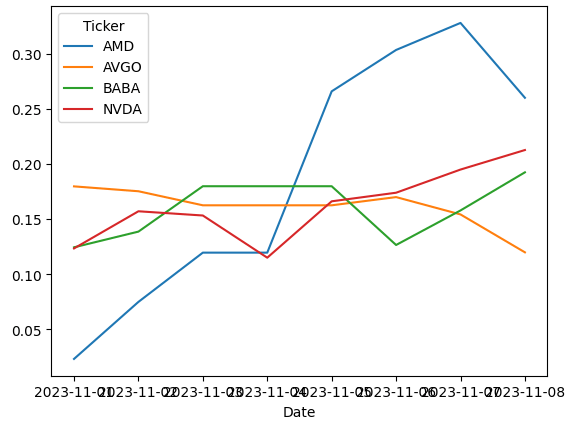
5-day EMA of the sentiment scores
By looking at the diagram above, it is easy to notice that the sentiment score of these four tickers ended up having different moving paths. However, the stock prices are not driven by the exact score but by the relative changes in the scores. Therefore, let’s take one more step to find out the changes in the emotional implications of these headlines.
1 | news_score.pct_change().dropna().plot() |
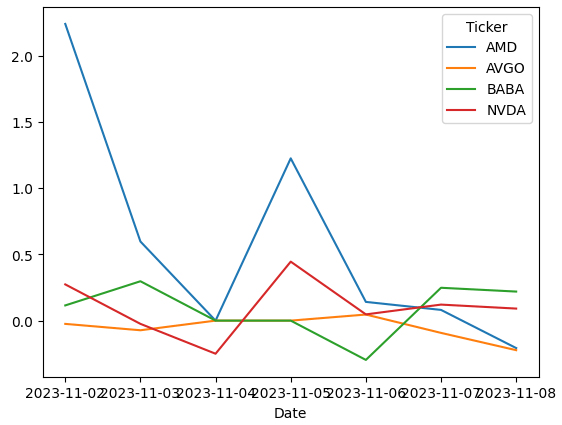
Percentage change of the daily sentiment score of each ticker
After these many steps, the outcome became much more clear at last. Both BABA and NVDA have positive changes in terms of the sentiment score changes. This might indicate that the stock prices of these two stocks possibly will have a positive influence and the demand of these two stocks would rise against the supply, leading the stock prices to go up.
Conclusion and other thoughts
This is the end of my sentiment analysis, but it shouldn’t be yours. There are actually more interesting things and ideas you can start building based on this sentiment framework, such as:
- Find a suitable lexicon when processing your token and when evaluating your scores.
- Scrape not just the headline of the news but also the content of the news to run a much more detailed sentimental analysis.
- Send the news_score data into the LSTM model instead of simply using the Exponential Moving Average.
- …
Welcome leaving a message to me telling me whether you like this article or not. Or, maybe just tell me what can be added to the analysis here.
Cheers.


